Technical Explanation of NLP for Fake News Detection

[Source]
Fake news and misinformation are ongoing issues and are in existence all around us in biased softwares that amplifies only our opinions for a “better” more seamless user experience. With the normalization of the internet and social media platforms, fake news and misinformation are turning into greater issues each day. The spread may be the result of different factors and incentives, however, each pose the same fundamental issue to humanity: the misunderstanding of what is true and what is false. This confusion may lead to more problems, such as a health crisis. One effective solution to this problem is the use of machine learning (ML) and natural language processing (NLP) algorithms to detect and flag fake news and misinformation, using pre-existing labeled datasets of true and false facts. In this article, I am going to explain why NLP provides a possible solution to this issue, the stages of the NLP pipeline from preprocessing to feature extraction and model training, and the problems that may arise from ML and NLP models. It has to be noted that companies such as Facebook and Twitter have already implemented systems to address fake news and misinformation, however, many challenges exist that have resulted in those systems not working as effectively as intended.
Natural Language Processing (NLP)
NLP is a sub-category of ML that has been advancing exponentially in the past few years thanks to the collection of more text-based data. It is one of the most important tasks that ML has been able to achieve, paving the way to the development of better voice assistants such as Alexa, better search engines, and much more. There are mainly two types of NLP: natural language understanding and natural language generation.
Natural Language Understanding (NLU)
NLU is when computers are able to “understand” or comprehend the meaning of a piece of text [Anand]. We as humans learn to understand some form of human language as we grow, and NLU gives computers the ability to do that based on collected data.
Natural Language Generation (NLG)
NLG is the response of NLP based on collected data [Anand]. This could be a reply by a mental chatbot software or the algorithm writing a full book. The goal of NLG is to achieve the level of speaking like a human. Some models such as the well-known GPT-3 have been able to achieve that kind of linguistic ability.
Fake news detection requires only natural language understanding, since we are not generating extra pieces of text. It is through NLP and NLU that the model is able to learn from the data and make decisions.
Fake news detection is the classification of a piece of text as misinformation or true information. It is either going to have an output of 0 or 1, fake or real. Based on that, it is indicated that fake news detection is similar to other applications of NLP, such as semantic analysis of restaurant reviews, and does not require any different method or new advanced technology to create a prototype.
The three main stages of NLP: preprocessing of input, feature extraction, and model training.
Preprocessing
The majority of the functions are in the preprocessing stage since the raw text cannot be directly inputted into a ML algorithm. The input data needs to go through a number of processes. The processes, which include tokenization, removal of stop words, stemming and lemmatization, and part of speech tagging as examples, will optimize and clean data for feature extraction, and eventually, model training.
Tokenization
Beginning with tokenization, it is the process of dividing raw text into smaller pieces, called tokens [“Tokenization”]. Tokens can be words, characters or subwords [Pai]. With that said, tokenization is usually used to separate sentences into words.
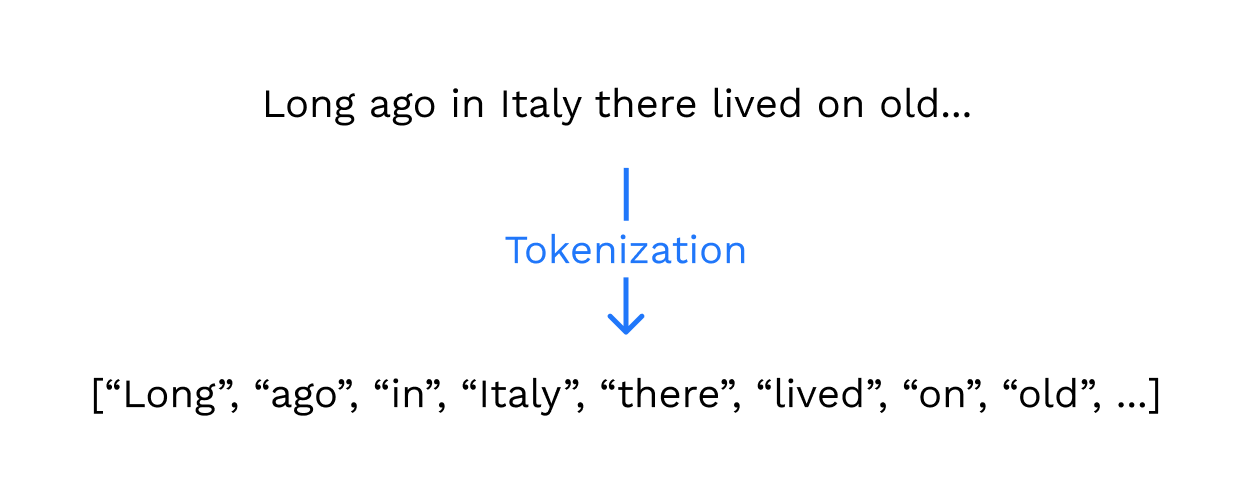
Image by Author
Tokenization is the fundamental building block of NLP [Pai]. In each type of NLP algorithm, whether it is fake news detection, a voice assistant, or a search engine, tokenization is required because it allows the ML algorithm to understand and infer from the relationship between a sequence of inputs, which are usually words [Chakravarthy].
Stop Word Removal
After this step, the new tokenized text will go through a specific function to remove stop words. Stop words are words that do not aid the ML algorithms in classifying a piece of text as fake or real, and therefore, should be removed [“Removing Stop Words with”]. For instance “the”, “is”, or “and” are all stop words [“English Stopwords”].

Image by Author
Stop word removal is necessary in order to reduce the size of the input, and enhance the time-efficiency of the ML algorithm both in training and validation [“Stop Word Removal”].
Stemming & Lemmatization
Stemming and lemmatization are functions that are applied to the dataset afterward. Stemming is the process that removes parts of a specific word to find the stem word [“Stemming”]. Lemmatization is similar fundamentally, but different in one part. In stemming, stem word may not be an actual literary word or term, whereas in lemmatization, lemma is an existing word [Beri]. With that said, both function are ways to find the root word, as illustrated .

Image by Author
Part-of-Speech (PoS) Tagging
Last but not least, another function that could be applied to the dataset is part of speech tagging. This is simply going through the dataset and tagging each token with its appropriate part of speech, whether that is a noun, pronoun, adjective, determiner, verb, adverb, preposition, conjunction, or interjection [Johnson]. This will help the ML algorithm with understanding the context, since certain words may have different meanings in different contexts. For example, the meaning of “rock” in “I sat on the rock” is different from “You rock!”
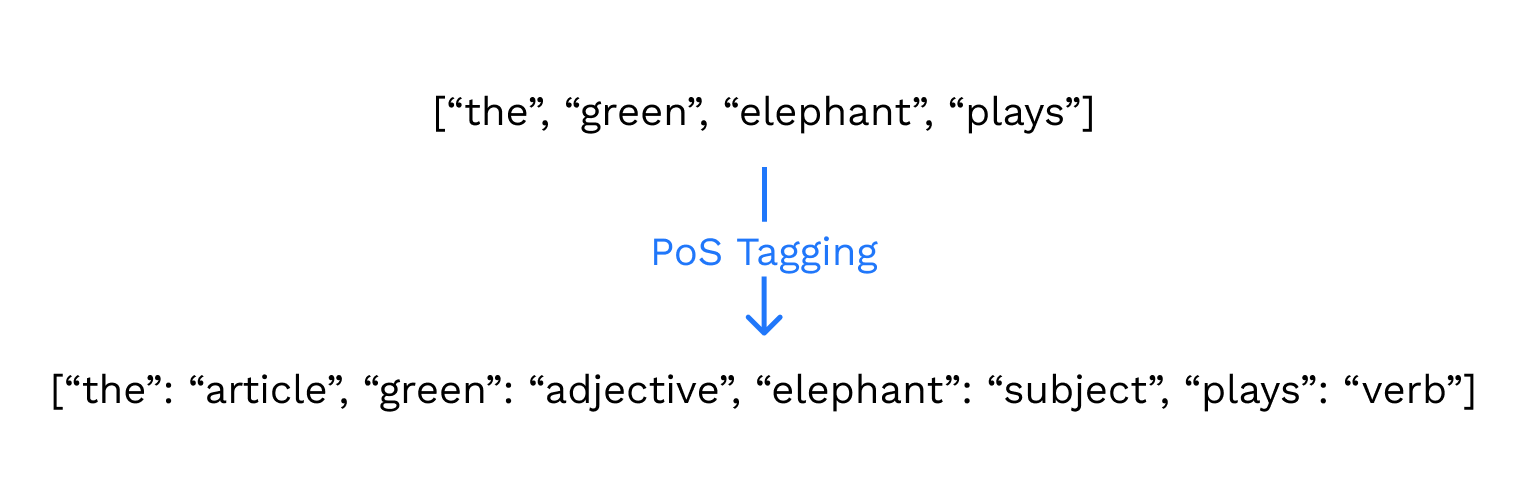
Image by Author
Other Functions
There are other preprocessing functions, including removal of punctuation that are applied to the input [Mundada]. These functions mainly address the cleanness, simplicity, and clarity of the data, and prepare data for following steps.
Example (All Preprocessing Steps)
As an example to include all the processes above, let's examine these sentences from one of Paul Graham’s essays: “It's not just a figure of speech to say that life is too short for something. It's not just a synonym for annoying. If you find yourself thinking that life is too short for something, you should try to eliminate it if you can” [Graham].
The final state of the text above after all the functions above may look like this: “just figure speech say life short thing just synonym annoy find think life short thing try eliminate”. As you can see, a sentence that had 44 words and 226 characters now only has 17 words and 100 characters. This will allow the ML algorithm to focus on the most important features of the text, not misled by other, less impactful factors.
It has to be noted that there are different NLP preprocessing libraries that may perform each function differently, however, the core principles are the same throughout.
Feature Extraction
Now, the raw text data has undergone certain functions for it to be cleaned of any misleading features or useless factors. However, the ML algorithm will still not understand text since it's a string. Thus, the text needs to be converted to vectors of numbers. The vector numbers will illustrate the linguistic features of the text [Brownlee]. This is called feature extraction or feature encoding [Brownlee]. Feature extraction is significant because it tackles the issue of how words are represented in the NLP pipeline [Brownlee; Takeuchi]. There are a number of feature extraction methods, with the two most popular ones being bag of words (BoW) and word embeddings [Takeuchi].
Bag of Words (BoW)
In BoW, each word is given an index in a vector of varied lengths determined by the purpose. That index will record the number of times the word appears in the specific text that is inputted [Brownlee]. For instance, consider the sentences “The happy dolphin named Clicker swam in the ocean.” In this case, the BoW model for this sentences may look similar to this:

Image by Author
Each word is associated with an index, and that index on the vector will count the frequency of that word in the sentences. The first index is associated with the first word of the sentences, called start of sentences (SOS) [Eremenko], while the second index is associated with the last word in the sentences, called end of sentences (EOS) [Eremenko]. The last index on the vector is associated with special words, such as names [Eremenko].

Image by Author
This method is called bag of words, because the position of the word in the sentences (or its Part-of-Speech (PoS) tag) does not matter. Instead, the frequency of the term is more significant. BoW is extremely simple to understand and to practically implement, and provides the flexibility to customize your text dataset. Additionally, if the application of the model is specific, BoW still functions accurately. However, it may also perform ineffectively if the relationship between words is significant in a piece of text [Brownlee; Ma].
It has to be noted that the BoW model will be created once the data has gone through all the preprocessing functions. meaning that there are not going to be any stop words or punctuations, and that all words are going to be stemmed and lemmatized. The illustration above still includes them for simplicity and clarity.
Word Embedding
One other method that has exponentially advanced the NLP industry is word embedding. Unlike the previous algorithm, this algorithm considers the relationship between words in a piece of text ["What Are Word Embeddings for Text?"]. Each word is given a multi-dimensional vector, and using a machine learning approach (i.e. Word2Vec, FastText, GloVe), the numeric vectors are used to determine whether words are similar in the context of different categories ["What Are Word Embeddings for Text?"; “NLP for Developers”].
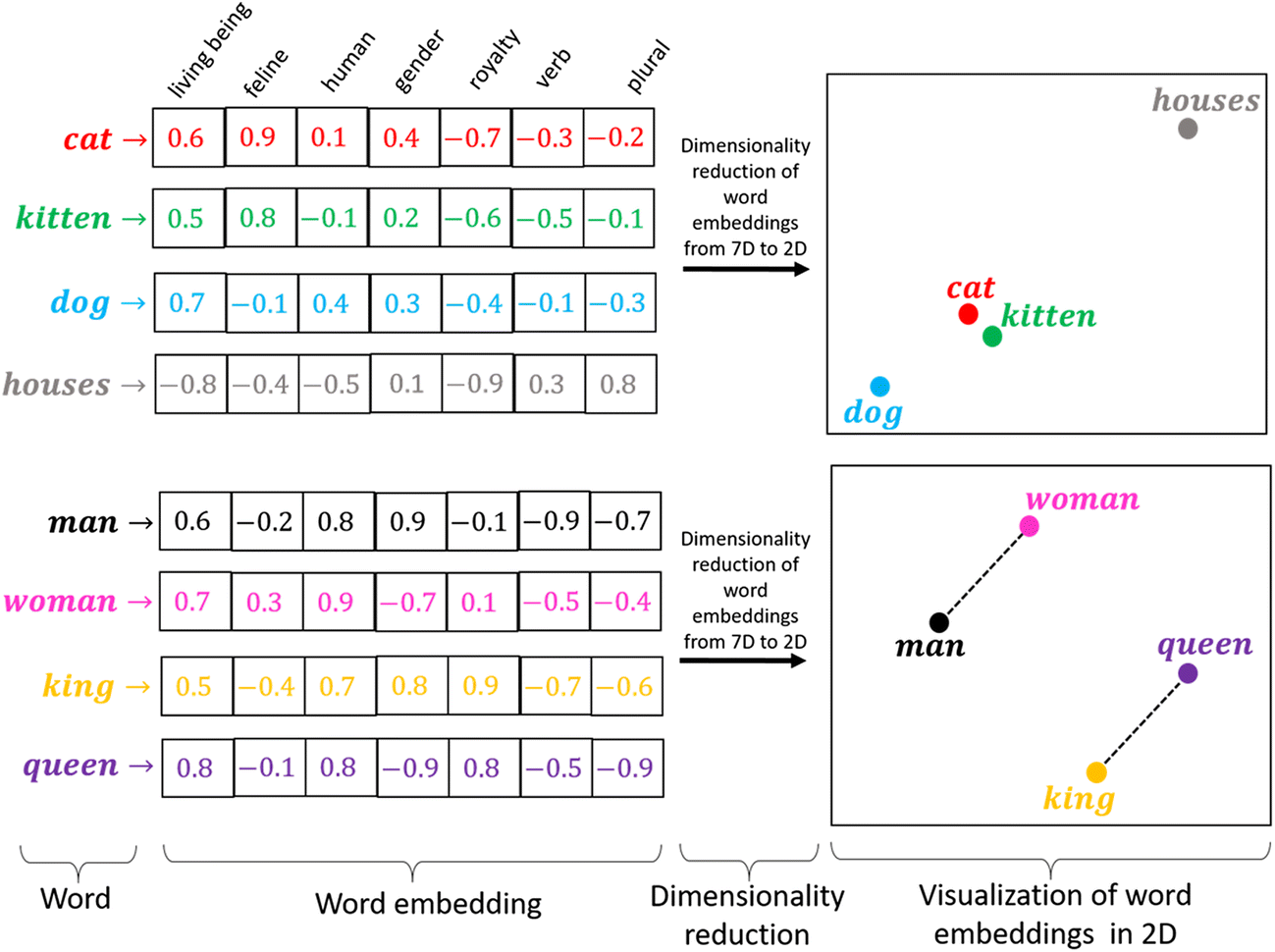
[Source]
Compared to BoW, word embeddings function much more effectively in situations where the deep linguistic analysis of the text is required–especially for fake new detection. However, I am going to use a BoW‘s baseline NLP model to present that it functions fairly effectively.
Model Training
Many different classification ML algorithms could be used to classify a piece of text as fake or real. I experimented with eight different classification algorithms (see Google Colab for Results), each returning different results, however, we are going to conceptually explain the ML algorithms that returned accuracies higher than 90%.
Logistic Regression
This algorithm is fit for problems that have a binary output of 0 or 1, true or false ["Logistic Regression for Machine Learning"]. The algorithm is not going to return a definite value of 0 or 1 (although it may), rather, it will return a probability between 0 or 1 [“"Logistic Regression for Machine Learning"; “Logistic Regression”].

Image by Author
The threshold value is usually 0.5, with outcomes higher than that returning 1 and vice versa [Harrison]. With that said, in certain scenarios, to take into account factors such as safety, the threshold value is modified. In our experiment, 0 indicates fake news and misinformation, while 1 indicates real and valid facts. Based on that, as an option to be more cautious, we could move the threshold value to higher than 0.5. That means if a text is given a probability of, for instance, 0.53, the outcome is still going to flag it as fake news to be more alert.
In our experiment, this algorithm, with a default threshold value of 0.5, returned the highest accuracy of 92.74%.
Stochastic Gradient Descent (SGD)
Gradient descent (GD) is the process of finding the lowest point on a surface, which is usually a graph [Srinivasan]. In ML, this algorithm is significant because it can be used to reduce the cost function, which is the difference between the experimental value and the theoretical value [Mc.]. For example, the value x on the lowest point of the graph below is 3. The goal of GD is to determine what the value of y is when x is 3.

Image by Author
SGD is similar to GD in that its goal is to minimize the error function, however, the process is more efficient. In GD, all samples of training data are used to modify one parameter (the number that affects the error function), however, in SGD, one sample training data is used to modify the parameter [Raschka].
SGD does not always return more accurate results than GD, but it does return adequately appropriate results in a short amount of time compared to GD. The result that was achieved using SGD in our experiment is 91.95%.
It has to be noted that the feature extraction method that was used was bag of words (BoW). All the results above and in the Google Colab were the result of a simple BoW model, which illustrates that even without word embeddings, a NLP model can perform fairly accurately.
Problems & Constraints
There are multiple problems regarding the ML model for fake news detection (or any other applications of NLP & ML) that should be noted.

[Source]
Biased Labels
The data is labeled by another human being who may naturally have their own opinions and biases. That may have affected the validity of the labels for each data, and hence, whether the dataset is overall reliable or not.
When designing a system such as this one, it is necessary for individuals and organizations to evaluate the labels of data themselves, and make sure that the data that is being used is not incorrect or invalid.
Ratio of Data
The ratio between the number of fake news and valid news also matters. ML algorithms perform their tasks by identifying features and assigning a certain value or weight to them. If there are, for example, 10 fake news and 5 valid news, the ML algorithm is naturally going to assign more value and weight to the features that appear in fake news, thinking that the dataset accurately illustrates the situation in the real world. The dataset that is being used for the algorithm should have an equal number of both types of data to remove any possible biases in those terms.
Biased System
Based on the assumption that the data is not biased, there is a possibility that the designed ML algorithm is biased. Data scientists and developers can often modify certain aspects of an ML algorithm based on its purpose and the situation. For that reason, they may add bias to the system. In certain scenarios, that is reasonable and in fact, appropriate, however, in others, that may lead to problems for others.
Age of Data
Our ML algorithm is trained and tested based upon data that was last updated two years ago. When we searched the dataset for the term Covid, nothing appeared. Based on that, we cannot expect accurate results if we test the model with Covid-related posts and articles.
This indicates that, since the dataset is from two years ago, it does not include information regarding new events and topics. The world is changing, therefore an ML algorithm from two years ago will not be as effective today.
The Validity of Real News & Information
The final and most significant problem regarding this NLP model specifically is that, even as humans, we are not 100% sure what is true and what is false. For some topics such as science, we are confident that the discoveries and breakthroughs are objectively true no matter the opinion or the bias of people around. In contrast, for other topics, this cannot be validated as confidently.
Having an algorithm that does not take into account the situation of the real world, and instead focuses solely on the inputted text can be very problematic and false. For instance, if it is stated that “the average lifetime of humans is 20 years on Earth”, the algorithm can classify the input as both real and fake based on the patterns that it identifies. The algorithm does not take into account information, such as research studies and surveys, which could be to some extent fake on their own.
Similarly, truths could be distorted and modified slightly for them to still be considered as a true statement from one perspective, but be misleading and false from another one. For instance, based on one statistics, different entities could make different interpretations and conclusions, and therefore, classify the data as true or false based on their own terms. Different perspectives have different opinions.
There also exists the degree of validity or fakeness. For instance, a whole article can be classified as fake and misinformation, but does that mean that each statistic and information stated in that article is fake and misinformation? That could be a possibility, but most likely, it is not. There could be some wrong statements throughout the article, but there could also be true ones. Based on that, an improved system should be able to classify smaller pieces of text based on a scale of, for instance, 1 to 10, with 1 being extremely fake and 10 being completely valid.
Based on the factors stated above, in this reality, we cannot clearly distinguish between what is true and what is fake other than the objective truth, which make it also harder for the computer to detect fake news and misinformation.
Implementation
The project that was completed to illustrate a minimum viable product can be accessed on GitHub using the link. There are comments to explain each line of code. For running the code or customizing it, simply copy the Google Colab and run each cell.
The dataset that was used for this project can be accessed on Kaggle using the link. This was an already-built dataset. Download it from Kaggle, and then upload it into the same folder as the created Jupyter notebook.
Conclusion
As examined, fake news detection algorithms provide many benefits, but also have many constraints and limitations. Using this system, fake news can be classified, leading to a more “real” future.
There are billions of pieces of data in the world, and as that increases, there has to be a system that will filter through it and select sources for us to utilize. These systems usually take the form of web browsers, however, unfortunately, the software that is performing this task for us has become biased based on different factors. For that reason, the main goal of this article is not to make people better data scientists (as it may), rather better thinkers and evaluators of the information and “wisdom” that is around us.
If you have any feedback on my writing style or have found a mistake in the essay, feel free to message me. Thanks for reading this article!
Acknowledgement
Thanks for all the feedback and suggestions from Omar Soliman.
Work Cited
Algolia. “What Is Natural-Language Understanding?” Algolia Blog, 24 Nov. 2020,
www.algolia.com/blog/product/what-is-natural-language-understanding/?utm_source=google&utm_medium=cpc_nonbrand&utm_campaign=Developer_Google_NAM_Search_NB_Blog_Dynamic&utm_content=blog&utm_term=&_bt=566443924544&_bk=&_bm=&_bn=g&_bg=130243782933.
Anand, Aman. “What Is Natural Language Processing? Recent Advances in the Field.” Educative, 7 Oct. 2020,
www.educative.io/blog/what-is-natural-language-processing#what-is.
Beri, Aditya. “Stemming vs Lemmatization.” Medium, Towards Data Science, 13 May 2020,
towardsdatascience.com/stemming-vs-lemmatization-2daddabcb221#:~:text=Stemming%20and%20Lemmatization%20both%20generate,words%20which%20makes%20it%20faster.
Brownlee, Jason. “A Gentle Introduction to the Bag-of-Words Model.” Machine Learning Mastery, 9 Oct. 2017,
machinelearningmastery.com/gentle-introduction-bag-words-model/#:~:text=A%20bag%2Dof%2Dwords%20model%2C%20or%20BoW%20for%20short,as%20with%20machine%20learning%20algorithms.&text=A%20bag%2Dof%2Dwords%20is,A%20vocabulary%20of%20known%20words.
---. “Logistic Regression for Machine Learning.” Machine Learning Mastery, 1 Apr. 2016,
machinelearningmastery.com/logistic-regression-for-machine-learning/#:~:text=Logistic%20regression%20is%20another%20technique,problems%20with%20two%20class%20values).&text=Techniques%20used%20to%20learn%20the,logistic%20regression%20model%20from%20data.
---. “What Are Word Embeddings for Text?” Machine Learning Mastery, 11 Oct. 2017,
machinelearningmastery.com/what-are-word-embeddings/.
Chakravarthy, Srinivas. “Tokenization for Natural Language Processing.” Medium, Towards Data Science, 10 July 2020,
towardsdatascience.com/tokenization-for-natural-language-processing-a179a891bad4.
“English Stopwords.” Stopwords, Ranks NL,
www.ranks.nl/stopwords.
Eremenko, Kirill. “Bag-of-Words Model.” Machine Learning A-Z™: Hands-On Python & R In Data Science,
https://www.udemy.com/course/machinelearning/
Graham, Paul. Life Is Short, Jan. 2016,
www.paulgraham.com/vb.html.
Harrison, Graham. “Calculating and Setting Thresholds to Optimise Logistic Regression Performance.” Medium, Towards Data Science, 2 May 2021,
towardsdatascience.com/calculating-and-setting-thresholds-to-optimise-logistic-regression-performance-c77e6d112d7e#:~:text=The%20logistic%20regression%20assigns%20each,0.5%20is%20the%20default%20threshold.
Johnson, Daniel. “POS Tagging with NLTK and Chunking in NLP [EXAMPLES].” Guru99, Guru99, 1 Jan. 2022,
www.guru99.com/pos-tagging-chunking-nltk.html#:~:text=POS%20Tagging%20(Parts%20of%20Speech,is%20also%20called%20grammatical%20tagging.
“Logistic Regression.” Logistic Regression - ML Glossary Documentation,
ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html.
Ma, Edward. “3 Basic Approaches in Bag of Words Which Are Better than Word Embeddings.” Medium, Towards Data Science, 22 May 2018,
towardsdatascience.com/3-basic-approaches-in-bag-of-words-which-are-better-than-word-embeddings-c2cbc7398016.
Mc., Conor. “Machine Learning Fundamentals (I): Cost Functions and Gradient Descent.” Medium, Towards Data Science, 27 Nov. 2017,
towardsdatascience.com/machine-learning-fundamentals-via-linear-regression-41a5d11f5220.
Mundada, Monica. “Basic Steps in Natural Language Processing Pipeline.” Medium, MLearning.ai, 7 Sept. 2020,
medium.com/mlearning-ai/basic-steps-in-natural-language-processing-pipeline-763cd299dd99.
Ng, Andrew. “Stanford Engineering Everywhere.” CS229 Lecture Notes, Stanford University,
web.archive.org/web/20180618211933/cs229.stanford.edu/notes/cs229-notes1.pdf.
“NLP for Developers: Word Embeddings | Rasa.” YouTube, YouTube, 16 Mar. 2020,
www.youtube.com/watch?v=oUpuABKoElw.
Pai, Aravindpai. “What Is Tokenization in NLP? Here’s All You Need To Know.” Analytics Vidhya, 26 May 2020,
www.analyticsvidhya.com/blog/2020/05/what-is-tokenization-nlp/#:~:text=Tokenization%20is%20a%20common%20task%20in%20Natural%20Language%20Processing%20(NLP).&text=Tokens%20are%20the%20building%20blocks,words%2C%20characters%2C%20or%20subwords.
Raschka, Sebastian. What's the Difference between Gradient Descent and Stochastic Gradient Descent?, 17 Nov. 2015,
www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent.
“Removing Stop Words with NLTK in Python.” GeeksforGeeks, 31 May 2021,
www.geeksforgeeks.org/removing-stop-words-nltk-python/.
Srinivasan, Aishwarya V. “Stochastic Gradient Descent — Clearly Explained !!” Medium, Towards Data Science, 6 Sept. 2019,
towardsdatascience.com/stochastic-gradient-descent-clearly-explained-53d239905d31.
“Stemming.” What Is Stemming? - Definition from Whatis.com, SearchEnterpriseAI,
www.techtarget.com/searchenterpriseai/definition/stemming.
“Stop Word Removal.” Stop Word Removal - IBM Documentation, IBM,
www.ibm.com/docs/en/watson-explorer/11.0.0?topic=analytics-stop-word-removal.
Takeuchi, Eiki. “Feature Extraction in Natural Language Processing with Python.” Medium, Eiki, 13 Jan. 2019,
medium.com/@eiki1212/feature-extraction-in-natural-language-processing-with-python-59c7cdcaf064#:~:text=Feature%20extraction%20mainly%20has%20two,used%20and%20has%20different%20approaches.
“TIP Sheet The Eight Parts of Speech.” Butte College, 19 Dec. 2019,
www.butte.edu/departments/cas/tipsheets/grammar/parts_of_speech.html#:~:text=There%20are%20eight%20parts%20of,as%20grammatically%20within%20the%20sentence.
“Tokenization”, Cambridge University Press, 2008,
nlp.stanford.edu/IR-book/html/htmledition/tokenization-1.html.